Data Science para previsão da votação do Impeachment
1. Introdução
Não é de hoje que Data Science é aplicado ao contexto político, mas podemos dizer que as eleições presidenciais dos EUA de 2008 foram um divisores de água para Data Science na política. A campanha de Barack Obama usou extensivamente Data Science, principalmente aplicado às redes sociais, para otimizar a campanha e arrecadar mais fundos, porém, a grande surpresa dessa eleição nesse conexto, foi estatístico Nate Silver que fez previsões no seu blog, o FiveThirtyEight, e acertou o resultado das eleições em 49 dos 50 estados.
Nate, que é autor do livro The Signal and the Noise: Why So Many Predictions Fail–but Some Don’t também foi extremamente feliz em suas previsões das eleições presidenciais do EUA em 2012 e acertou o resultado das eleições em 50 dos 50 estados. Com isso, a internet começou a fazer brincadeiras baseadas no Chuck Norris Facts e criaram a hashtag #NateSilverFacts.
Após esses fatos, Data Science tem sido bastante utilizado na política, inclusive, a ponto, de chegar até em seriados como House of Cards, onde podemos ver o personagem Aidan fazendo uma análise de sentimento durante um debate realizado entre Underwood e Conway.
No contexto brasileiro, ainda vemos poucas iniciativas nesse sentido, e diante das incertezas que precedem a votação do impeachment da presidente Dilma Rousseff, esse artigo visa utilizar uma abordagem de Data Science para tentar prever o resultado da votação do Impeachment.
2. Problema
A definição do nosso problema é: prever os votos dos deputados na votação de abertura do impeachment da presidente Dilma Rousseff a ser realizado na Câmara dos Deputados, ou seja, fazer uma previsão da votação do Impeachment
No caso, a abertura de impeachment ocorre se dois terços (342) dos 513 deputados votarem a favor, ou seja, o processo de impeachment é aberto se 342 deputados ou mais votarem a favor.
Para entender melhor todo o processo de impeachment da presidente Dilma Rousseff, sugiro a visualização desse especial realizado pelo G1.
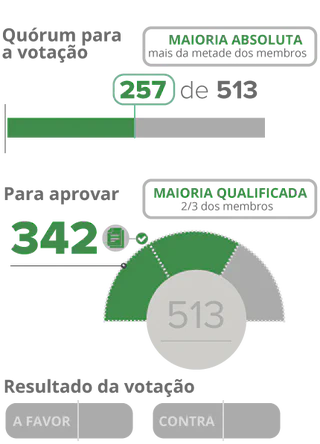
Fonte: G1
3. Dados
Para prevermos os votos dos deputados, iremos utilizar as seguintes informações:
- Nome do Deputado
- Partido
- Estado
- Votos realizados na Câmara dos Deputados em 2015
- Manifestação de Voto
3.1 Fontes
Esses dados foram coletados do site do Mapa do Impeachment do Movimento Vem Pra Rua Brasil e do Radar Parlamentar do Grupo de Estudos de Software Livre da POLI-USP.
Entrando mais no detalhe, os dados dos Votos realizados na Câmara dos Deputados em 2015 foi obtido no Radar Parlamentar e o restante no Mapa do Impeachment.
3.2 Pré-processamento
É importante notar, que houve um trabalho da obtenção, principalmente, com relação aos Votos realizados na Câmara dos Deputados em 2015, onde foi necessário importar à Base de Dados do Radar Parlamentar (demorou aproximadamente 6 horas) no PostgreSQL, realizar uma consulta no banco de dados para obter os dados necessários e depois exportar esses dados em formato CSV. Já a outra parte foi facilitado pelo arquivo disponibilizado no post do Regis A. Ely sobre o impeachment
Após a exportação dos dados da consulta, temos os seguintes dados:

É importante notar que os dados de voto estão no formato Long e para adequar para o processamento de um modelo, temos que colocar no formato Wide. Após a conversão de Long para Wide, temos o seguinte resultado:
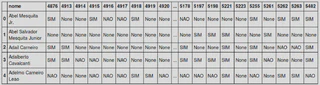
Então, após a conversão, os números nas colunas se referem ao votacao_id e os votos nas linhas.
Após isso, realizei um cruzamento entre a base de dados com os Votos realizados na Câmara dos Deputados em 2015 com a base de dados do Mapa do Impeachment e cheguei nesse resultado:
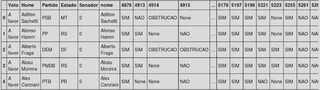
Como já mostrado na tabela anterior as opções de voto, podem ser:
- ABSTENCAO
- OBSTRUCAO
- SIM
- NAO
- None (Quando não há nenhum registro do deputado naquela votação)
Com isso, podemos ver que em cada votação temos uma variável categórica e para que o nosso modelo entenda melhor a separação das categorias iremos fazer um processo de Dummy Coding onde teremos uma matriz esparsa.
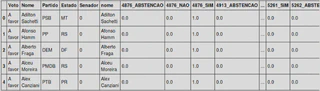
Ainda, as variáveis Partido e Estado também são categóricas, portanto, devemos fazer o mesmo processo com elas.
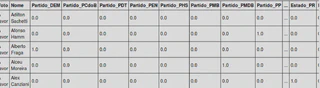
E assim chegamos a base de dados pré-processada, com 513 linhas e 888 colunas (listadas abaixo):
- Nome
- 26 Partidos
- 27 Estados
- 833 com relação aos Votos realizados na Câmara dos Deputados em 2015
- Manifestação de Voto
4. Modelo
Pela etapa dos dados anterior, podemos atestar o gráfico da matéria da Forbes que diz que um cientista de dados gasta aproximadamente 80% do seu tempo preparando os dados.
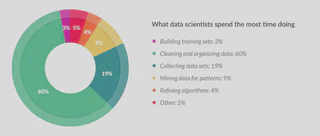
Fonte: Forbes
Mas vejamos pelo lado bom, chegamos na parte que os cientistas de dados mais gostam, que é a parte de aplicar os algoritmos nos dados, verificar padrões e fazer previsões.
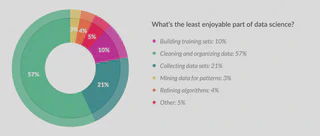
Fonte: Forbes
Pois bem, agora, antes de escolhermos qual modelo iremos aplicar, precisamos definir qual a métrica que vai definir o quão satisfatório é o nosso modelo.
4.1 Métrica
No caso, nosso problema é de classificação binária (A favor ou Contra) e para esse tipo de problema temos o seguinte conjunto de métricas que costumam ser utilizadas:
- Accuracy Score
- Average Score
- F1 Score
- Precision
- Recall
- Log Loss
Para efeitos de simplicidade, iremos escolher a Accuracy Score que é definida pela seguinte fórmula:
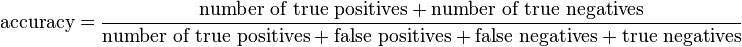
4.2 Validação
Pronto, agora que temos a métrica definida vamos escolher o método de validação cruzada para verificar a generalização do modelo ao prever dados que podem ser diferentes do conjunto de treinamento, dentre as possibilidades temos:
- KFold
- Stratified KFold
- Leave One Out
- Leave One Label Out
Nesse problema, usaremos o Stratified KFold, pois ele preserva a distribuição da Manifestação de Voto em cada particionamento, e também, usaremos 10 partições para aumentar o grau de confiança da validação.
4.3 Escolha do Modelo
Agora, chegamos a parte da escolha do modelo, no caso, para se fazer esse tipo de escolha devemos levar em consideração alguns aspectos como:
- Perfomance de Previsão
- Eficiência Computacional
- Interpretabilidade
Nesse caso, como nosso post preza pelo entendimento do leitor, iremos escolher um modelo que possui boa interpretabilidade. Alguns modelos que cumprem esse requisito são:
- Regressão Logística
- Árvore de Decisão
Nesse caso, o modelo de Árvore de Decisão possui mais interpretabilidade, portanto, esse será o modelo escolhido.
4.4 Aplicação do Modelo
Então, para recapitular definimos a aplicação do nosso modelo da seguinte maneira:
- Métrica: Accuracy Score
- Validação: Stratified KFold com 10 partições
- Modelo: Árvore de Decisão
Agora, finalmente, chegamos à etapa de aplicação do modelo, onde usaremos 383 deputados que manifestaram voto para nosso conjunto de treinamento e validação e 129 deputados indecisos ou que não manifestaram seu voto para nosso conjunto de previsão.
Ao aplicarmos nossa árvore de decisão, limitei a profundidade até o nível 5 para facilitar a intepretação e então cheguei aos seguintes resultados:
Validação Cruzada:
- 0.88 de acurácia média
- 0.05 de desvio padrão
E uma das features mais interessantes da Árvore de Decisão, é que podemos ver variáveis e sua importância:
('5102_NAO', 0.48907282961971399), ('5166_NAO', 0.15440994106912861), ('5147_NAO', 0.077740704874052796), ('4999_NAO', 0.057152833759791341), ('5041_SIM', 0.052028491272337517), ('5085_SIM', 0.03781403149400113), ('Partido_PDT', 0.027263326073109304), ('Partido_PT', 0.02676308155800626), ('5109_NAO', 0.023867802734912871), ('5177_NAO', 0.022672717568444675), ('5032_SIM', 0.017145850127937404), ('4986_ABSTENCAO', 0.014068389848564032)
E essa é a árvore de decisão que chegamos:
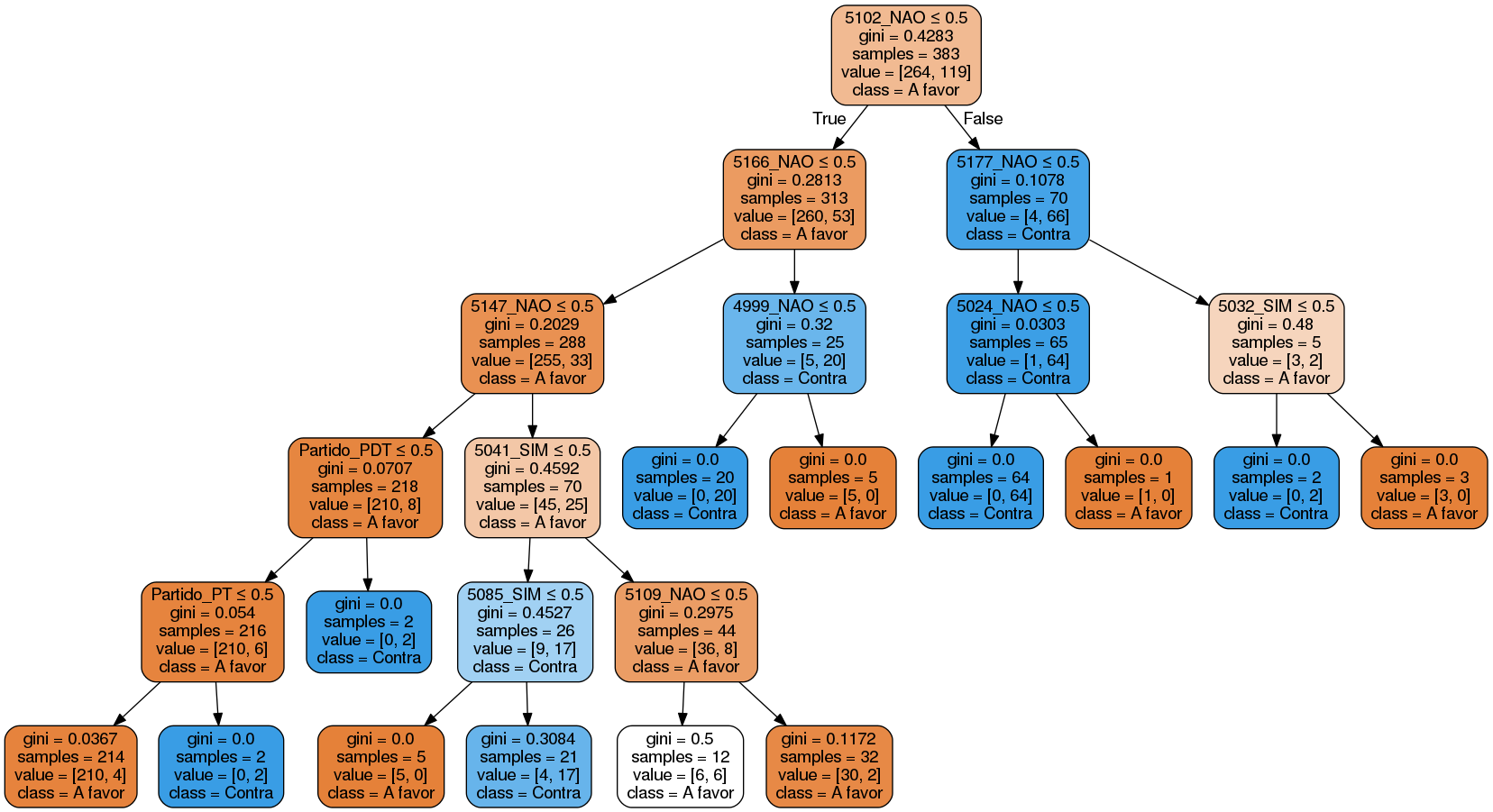
Para você entender melhor, tomemos por exemplo, a raiz da nossa árvore que tem o 5102_NAO <= 0.5, que basicamente diz, se o deputado votou NAO (NAO=1, SIM=0) na votação 5102, provavelmente ele é contra. Caso ele tenha não tenha votado (NAO=0, SIM=0) ou tenha votado SIM (NAO=0, SIM=1) ele provavelmente é à favor.
Ainda, segue tabela abaixo para fazermos um paralelo dos códigos de votação (ver coluna votação). É importante notar que cada projeto pode ter várias votações e a votação pode ser apenas referente à uma parte do projeto, ou seja, uma votação não necessariamente implica que um deputado é à favor ou contra o projeto inteiro.
| sigla | numero | votacao | peso_vot | descricao_votacao | ano |
|---|---|---|---|---|---|
| MPV | 661 | 5102 | 0.4890 | Sigilo BNDES | 2014 |
| PL | 1057 | 5166 | 0.1544 | Infantícidio | 2007 |
| MPV | 685 | 5147 | 0.0777 | PRORELIT | 2015 |
| PLP | 302 | 4999 | 0.0572 | Domésticas | 2013 |
| PEC | 171 | 5041 | 0.0520 | Maioridade Penal | 1993 |
| PL | 2960 | 5085 | 0.0378 | Repatriação | 2015 |
| MPV | 672 | 5109 | 0.0239 | Salário Mínimo | 2015 |
| PL | 10 | 5177 | 0.0227 | Seguro de Vida para Funcionários | 2015 |
| MPV | 665 | 5032 | 0.0171 | Seguro Desemprego Pescador | 2014 |
| PEC | 443 | 4986 | 0.0141 | Aumento para AGU e Delegados | 2009 |
Como podemos ver, são alguns projetos polêmicos e isso nos dá a comprovação e um insight de que verificar votações de projetos polêmicos pode ser um bom indicador de como o deputado votará em um outro projeto polêmico, como é a votação do impeachment.
5. Resultados
Por fim, segue os resultados, com as previsões de votações dos indecisos e depois a previsão considerando os 513 deputados.
5.1 Previsão de Votação dos Indecisos
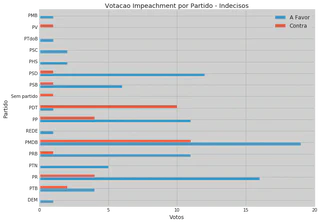
| Partido | A Favor | Contra |
|---|---|---|
| DEM | 1 | 0 |
| PDT | 1 | 10 |
| PHS | 2 | 0 |
| PMB | 1 | 0 |
| PMDB | 19 | 11 |
| PP | 11 | 4 |
| PR | 16 | 4 |
| PRB | 11 | 1 |
| PSB | 6 | 1 |
| PSC | 2 | 0 |
| PSD | 12 | 1 |
| PTB | 4 | 2 |
| PTN | 5 | 0 |
| PTdoB | 1 | 0 |
| PV | 0 | 1 |
| REDE | 1 | 0 |
| Sem partido | 0 | 1 |
| Total | 93 | 36 |
5.2 Previsão de Votação
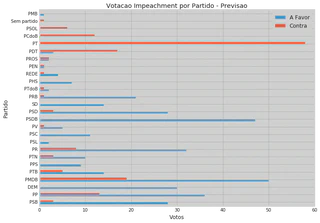
| Partido | A Favor | Contra |
|---|---|---|
| DEM | 30 | 0 |
| PCdoB | 0 | 12 |
| PDT | 3 | 17 |
| PEN | 1 | 1 |
| PHS | 7 | 0 |
| PMB | 1 | 0 |
| PMDB | 50 | 19 |
| PP | 36 | 13 |
| PPS | 9 | 0 |
| PR | 32 | 8 |
| PRB | 21 | 1 |
| PROS | 2 | 2 |
| PSB | 28 | 3 |
| PSC | 11 | 0 |
| PSD | 28 | 3 |
| PSDB | 47 | 0 |
| PSL | 2 | 0 |
| PSOL | 0 | 6 |
| PT | 0 | 58 |
| PTB | 14 | 5 |
| PTN | 10 | 3 |
| PTdoB | 2 | 1 |
| PV | 5 | 1 |
| REDE | 4 | 1 |
| SD | 14 | 0 |
| Sem partido | 0 | 1 |
| Total | 357 | 155 |
De acordo com a nossa previsão, teremos 357 votos à favor e 155 votos contra, portanto, isso significa que a previsão considera que o processo de abertura de impeachment será aberto.

Ainda, creio que seja possível melhorar a perfomance da previsão com outros tipos de modelo ou hiperparametrização e caso eu tenha tempo, publicarei uma nova previsão usando um outro modelo com parâmetros otimizados.
6. Agradecimentos
Agradeço à Bruna Ferreira dos Santos pela revisão desse artigo e à Leonardo Leite do Radar Parlamentar pela ajuda com a base de dados do Radar Parlementar.
